[ML] 3-1. 평가 - 오차행렬과 정확도
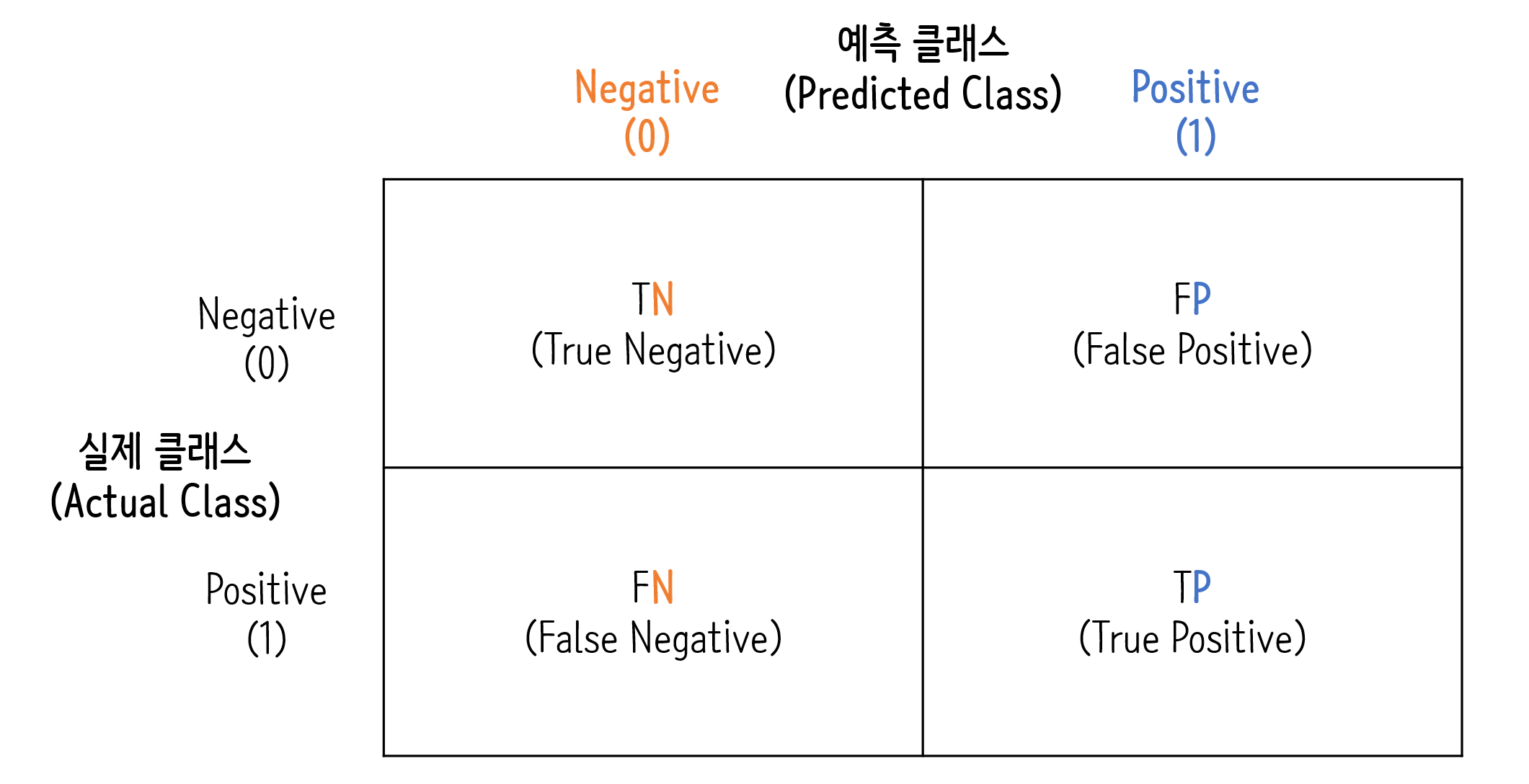
오차 행렬
오차행렬(confusion matrix)는 학습된 분류 모델이 예측을 수행하면서 어떠한 유형의 예측 오류가 발생하고 있는지는 보여주는 지표
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator
from sklearn.metrics import accuracy_score
import numpy as np
import pandas as pd
class MyFakeClassifier(BaseEstimator) :
def fit(self, X, y) :
pass
# 입력값으로 들어오는 X 데이터 세트의 크기만큼 모두 0값으로 만들어서 반환
def predict(self, X) :
return np.zeros((len(X), 1), dtype=bool)
# 사이킷럿의 내장 데이터 세트인 load_digits()를 이용해 MNIST 데이터 로딩
digits = load_digits()
# digits 번호가 7번이면 True이고 이를 astype(int)로 1로 변환, 7번이 아니면 False이고 0으로 변환.
y = (digits.target == 7).astype(int)
X_train, X_test, y_train, y_test = train_test_split(digits.data, y, random_state=11)
from sklearn.metrics import confusion_matrix
# Dummy Classifier로 학습 및 예측
fakeclf = MyFakeClassifier()
fakeclf.fit(X_train, y_train)
fakepred = fakeclf.predict(X_test)
confusion_matrix(y_test, fakepred)
array([[405, 0],
[ 45, 0]], dtype=int64)
정확도
예측 결과와 실제 값이 동일한 건수 / 전체 데이터 수
단순히 모델의 성능을 정확도로 판단하기에는 무리가 있음 (ex. 이진 분류 모델에서 0의 비율이 압도적으로 많은 데이터의 경우 입력값이랑 상관없이 단순히 0으로 출력해도 정확도가 좋기 때문)
$(TN + TP) \over (TN + FP + FN + TP)$
from sklearn.metrics import accuracy_score
print('오차 행렬')
print(confusion_matrix(y_test, fakepred))
print('\n모든 예측을 0으로 할 때의 정확도는 : {:.3f}'.format(accuracy_score(y_test, fakepred)))
오차 행렬
[[405 0]
[ 45 0]]
모든 예측을 0으로 할 때의 정확도는 : 0.900
Comments